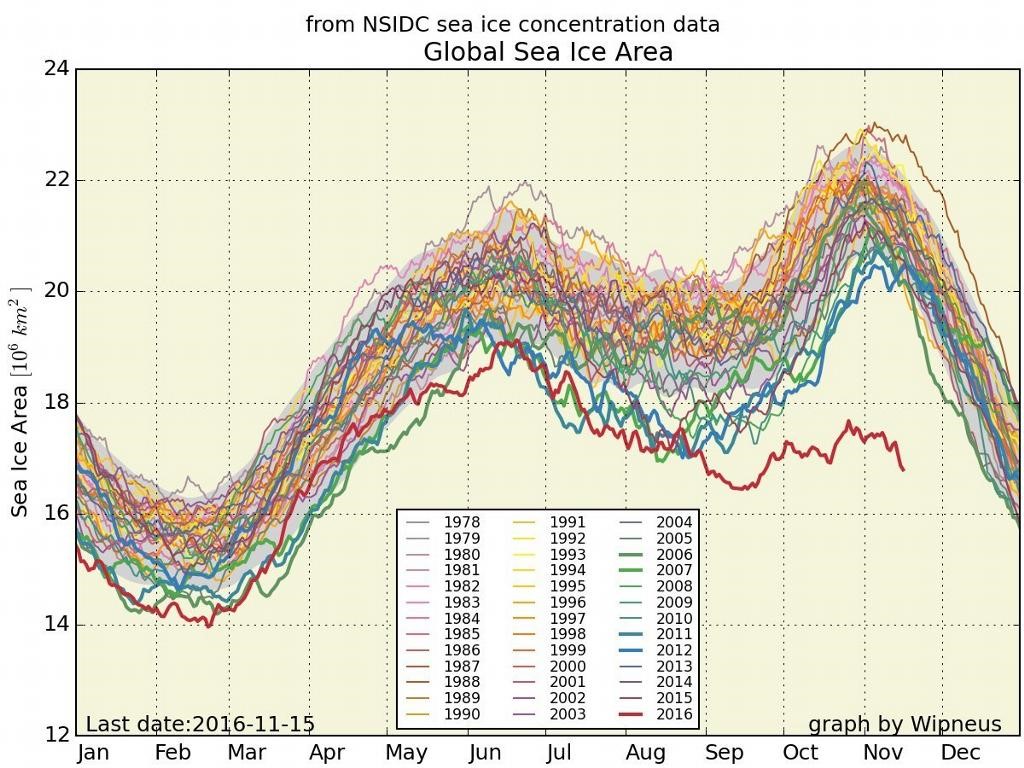
Background: The Port Mann Bridge is a ten-lane cable-stayed bridge that spans the Fraser River east of Vancouver, B.C. At the time of its opening in 2012, it was the widest bridge in the world at 65 m (213 ft). It is a key artery for Metro Vancouver, with about 100,000 crossings per day.

What Happened: Shortly after opening, during a winter storm in December 2012, “ice bombs” – clumps of ice and snow, dropped from the overhead cables, hitting and damaging over 300 vehicles. Windshields were broken, and dents were left in roofs and along the sides of cars. A few people suffered injuries during the incident.

Proximate Cause: Insufficient measures were in place to mitigate the hazard of ice and snow falling from the overhead cables, which, in the case of the Port Mann bridge, cross over the roadway. The contract between Transportation Investment Corporation (TI Corp.), the Crown corporation responsible for the Port Mann, and Kiewit/Flatiron General Partnership, included the requirement that “Cables and structure shall be designed to avoid ice build-up from falling into traffic.” The bridge’s designer maintained that measures including spacing the cable anchors away from traffic, using central pylons which avoid large cross frames over traffic, and using HDPE stay pipes were sufficient to minimize the risks associated with snow and ice accumulation.
Underlying Issues: There were many parties involved in the issue – the owner/operator, the design-build contractor, the maintenance contractor, and consultants. An analysis of the documentation and internal emails on the issue (from a freedom of information request done by an independent journalist) shows that none of the parties really “owned” the issue, but rather they assumed that either the risk was negligible or at least sufficiently managed, or that someone else would take care of the risk mitigation.
The issue of falling ice and snow from cable-supported bridges is well known. Examples can be found with bridges in Denmark, Sweden, Japan, the U.K., and in the U.S., including the Tacoma Narrows Bridge in Washington state. Methods to manage the risk are also well documented, although in many cases there are few practical solutions beyond traffic closure.
Ice and snow accretion removal systems can be mechanical, thermal, or passive in nature. In addition, localized monitoring of weather and ice/snow build-up can be used to pre-emptively close individual traffic lanes or the entire bridge when necessary. Finally, the basic choice of having vertical cable planes instead of inclined cable planes (“fanned” cables suspended over traffic) can reduce the risk.
Aftermath: B.C.’s transportation minister blamed the design-build contractor, Kiewit/Flatiron, stating that the bridge did not meet the requirements. The provincial automobile insurance agency, ICBC, paid $400,000 in claims, and lawsuits were filed by people who were injured during the incident. In response to one of the civil claims, TI Corp. and Kiewit/Flatiron stated “The buildup and subsequent release of ice and snow from the bridge structure was the result of a confluence of extreme environmental conditions, both unforeseen and unforeseeable to the defendants or any of them and was the inevitable result of an Act of God”.
Despite that statement, cable collars were installed in the fall of 2013 to help mitigate the hazard. These are manually released from the top of the towers and slide down the cable stays to dislodge accumulated snow and ice. The intent is to do this frequently enough to ensure the dislodged pieces are small enough to avoid damage to vehicles below.
In addition, a weather station and cameras were installed to allow for monitoring of conditions that could lead to ice and snow accumulation on the cables. Operating procedures were put in place to shut down the bridge if dangerous conditions were detected.
The Port Mann collar system is said to be one of the most successful systems in the world. However, it is not fool-proof. Snowfalls during December 2016 have so far resulted in about 50 insurance claims from falling ice and snow. This may have been a result of the operators not deploying the collars early enough during rapidly-changing weather conditions.
Interestingly, over the same period, 95 claims resulted from the same situation occurring on another Vancouver area bridge, the Alex Fraser, which has cables that do not hang over the bridge deck. High winds together with rising temperatures can blow ice and snow off the cables into traffic. The bridge was shut down for several hours on two days, due to “ice bombs”. Falling ice also occurred in 2005, 2008, and 2012, but overall the Alex Fraser is less prone to these incidents than the Port Mann. As a temporary measure, the Ministry of Transportation indicated that for the Alex Fraser, it will use a heavy-lift helicopter to blow snow accumulations off the cables.
The experiences on the Port Mann as well the Alex Fraser bridges will be applied to the upcoming bridge to replace the George Massey Tunnel. In particular, the cable stays will not be allowed to cross over traffic and cable collars or an improved alternative will be required.
Lessons Learned:
- The requirements were written in a way that left the criticality and expectations somewhat open to interpretation. For some, the word “avoid” means you must completely ensure no risk of an incident. For others, avoid means “try” or “use typical means and methods”. One other section in the listed standards specified “practical” solutions were acceptable. Yet, unless specifically defined, the word “practical” allows for many different measures of acceptable implementation. The expectations around acceptable public safety were not met in this case, and best practices around requirements for public safety are typically better defined than what existed for the Port Mann Bridge.
- Designers should account for the complete system and its operating environment. The micro-climates of Vancouver are well known, and hazardous when heavy wet snow is mixed with freezing and thawing conditions.
- Repeated questions raised regarding the risks of falling ice and snow could have resulted in a risk analysis leading to a more effective ice hazard mitigation strategy, rather than simply assuming the original design would be adequate.
- Public safety issues need to be considered carefully and critically, and receive considerable attention from management.
- Ultimately, the Owner is most likely to be held responsible for the performance of the implemented design and its impact on third parties (in this example, motorists being hit by “ice bombs”). While many projects have multiple contractors and parties involved in the design, construction, operation and maintenance, the Owner team needs to ensure that there is sufficient capability, staffing, mandate, and expertise held by these parties to be able to ensure quality in requirements definition and in the design, build, verification, validation, and operation and maintenance stages to mitigate issues.
Michael Eiche, P.Eng. Principal, SysEne Consulting